Context Engineering: Die 4 Stufen der KI-Kompetenz
Context Engineering: Warum gute Prompts nicht mehr reichen
Sie haben den perfekten Prompt geschrieben. Rolle, Kontext, Aufgabe, Format. Alles nach Lehrbuch. Und trotzdem liefert die KI generischen Output, der nicht zu Ihrem Unternehmen passt.
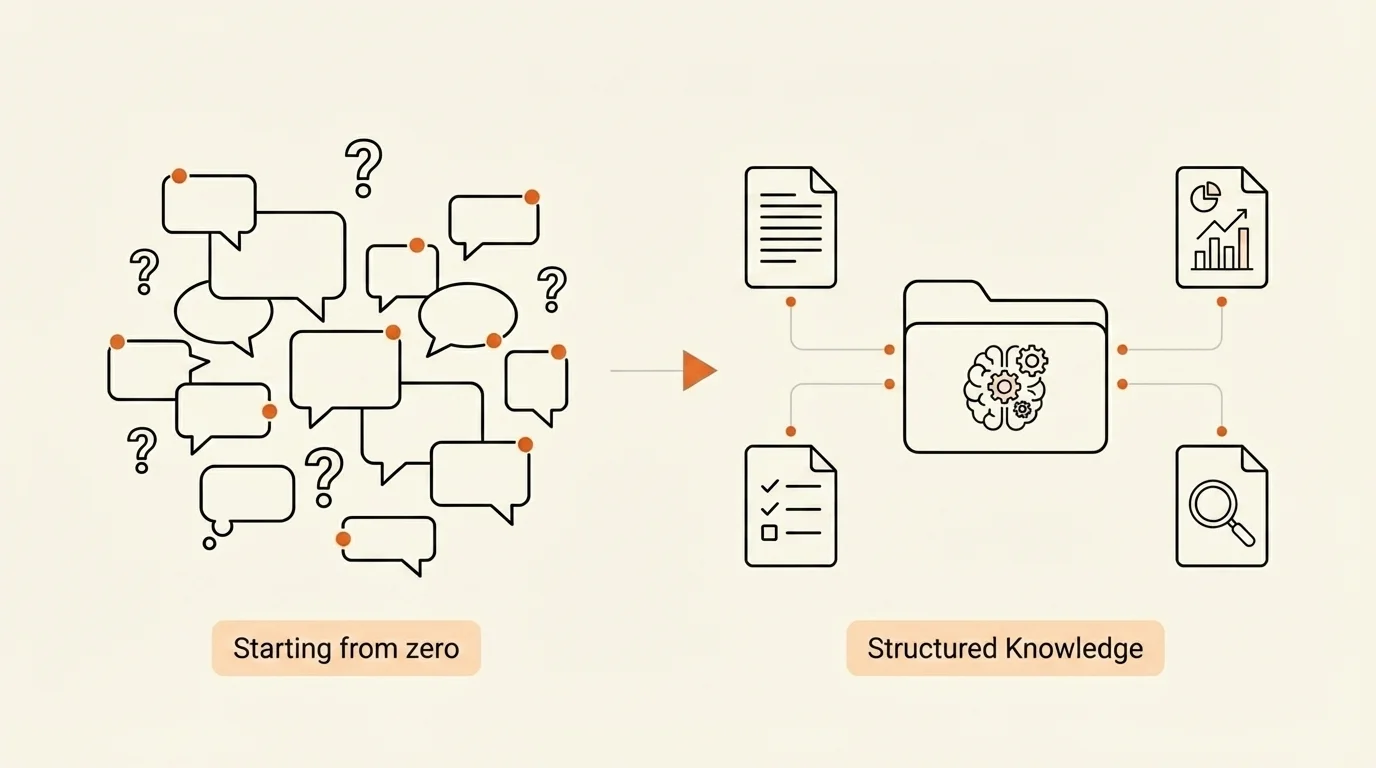
Das Problem liegt nicht am Prompt. Es liegt daran, dass Sie jedes Mal bei Null anfangen.
Context Engineering löst genau dieses Problem. Statt der KI bei jeder Anfrage zu erklären, wer Sie sind, was Ihr Unternehmen macht und welche Standards gelten, hinterlegen Sie dieses Wissen einmalig. Die KI greift automatisch darauf zu. Jedes Mal.
In diesem Artikel zeige ich Ihnen die 4 Stufen der KI-Kompetenz, warum Context Engineering die wichtigste davon ist und wie Sie mit einer einfachen Wissensdatenbank sofort starten können.
Was ist Context Engineering?
Context Engineering beschreibt, wie Sie einer KI dauerhaft den Kontext Ihres Unternehmens vermitteln. Nicht über einzelne Prompts, sondern über strukturiertes Wissen, das bei jeder Interaktion automatisch zur Verfügung steht.
Der Unterschied zu Prompt Engineering: Beim Prompt Engineering optimieren Sie die einzelne Anweisung. Beim Context Engineering optimieren Sie das Wissen, auf das die KI zugreift, bevor sie Ihre Anweisung überhaupt erhält.
Ein Beispiel: Wenn Sie Ihren KI-Agenten bitten, einen Social-Media-Beitrag zu erstellen, müssen Sie nicht jedes Mal erklären, welche Sprache Sie verwenden, welche Wörter Sie vermeiden und wie lang Ihre Sätze sein sollen. Das steht in den Regeln. Einmal definiert, immer beachtet.
Die 4 Stufen der KI-Kompetenz
KI-Kompetenz entwickelt sich in vier Stufen. Jede baut auf der vorherigen auf. Die meisten Unternehmen stecken noch bei Stufe 1 fest.
Stufe 1: Prompt Engineering
Das war 2022 bis 2024 die zentrale Fähigkeit: Wie formuliere ich eine Anweisung an die KI, damit ich den Output bekomme, den ich möchte?
Die Formel war einfach: Rolle + Kontext + Aufgabe + Format. „Du bist ein Marketing-Experte. Mein Unternehmen verkauft X. Schreibe mir einen LinkedIn-Post. Maximal 200 Wörter.”
Das funktioniert. Aber es hat einen entscheidenden Nachteil: Sie starten jedes Mal bei Null. Jeder neue Chat bedeutet, dass Sie der KI erneut erklären müssen, wer Sie sind, was Ihre Brand-Guidelines sind und wie Ihre Prozesse ablaufen.
Stufe 2: Context Engineering
Hier passiert der entscheidende Sprung. Statt der KI alles im Prompt zu erklären, definieren Sie den Kontext einmalig als Regel.
Was gehört in den Kontext?
- Unternehmensidentität: Wer sind Sie? Was macht Ihre Firma? Wer ist Ihre Zielgruppe?
- Standards: Welche Sprache verwenden Sie? Welche Wörter sind tabu? Wie lang sollen Sätze sein?
- Prozesse: Wie läuft Ihr Angebotsprozess ab? Welche Schritte hat Ihr Onboarding? Wie erstellen Sie Content?
- Wissen: Welche Projekte haben Sie abgeschlossen? Was sind Ihre Preise? Welche Case Studies gibt es?
Der Schlüssel: Möglichst präziser Kontext mit minimaler Wortanzahl. Nicht alles reinpacken, was Ihnen einfällt. Sondern genau das, was die KI für ihre Aufgaben braucht.
Wenn ich heute sage „Erstell mir ein Angebot für diesen Kunden”, weiß mein KI-Agent bereits: Wie meine Angebotsvorlage aussieht, welche Projekte ich bisher gemacht habe, was meine Stundensätze sind und wie der Prozess nach dem Angebot weitergeht. 5 Minuten nach einem Erstgespräch ist das personalisierte Angebot fertig. Früher hat das 2-3 Stunden gedauert.
Stufe 3: Intent Engineering
Was nützt der perfekte Kontext und der perfekte Prompt, wenn das Ziel falsch definiert ist?
Das bekannteste Beispiel: Klarna. Der Zahlungsdienstleister setzte KI im Kundenservice ein und sparte 40 Millionen Euro. Klingt nach Erfolg. War es aber nicht.
Das Problem: Die KI hatte ein Ziel: Ticketzeiten reduzieren. Genau das hat sie getan. Sie hat Tickets so schnell wie möglich geschlossen, sich strikt an Richtlinien gehalten und keine Ausnahmen gemacht. Das Ergebnis: Die Kundenzufriedenheit ist eingebrochen.
Hätte Klarna das Ziel anders definiert, zum Beispiel „Ticketzeiten reduzieren bei gleichbleibender Kundenzufriedenheit”, hätte die KI abgewogen: Wo kann ich schneller sein? Wo muss ich mir mehr Zeit nehmen, damit der Kunde zufrieden bleibt?
Intent Engineering bedeutet: Das richtige Ziel definieren, nicht nur das offensichtliche.
Stufe 4: Specification Engineering
Die Königsdisziplin. Hier spezifizieren Sie so präzise, dass ein KI-Agent komplett autonom arbeiten kann.
Am Beispiel Klarna: Specification Engineering hätte bedeutet, klare Regeln für Grenzfälle zu definieren. „Wenn der Kunde zum dritten Mal anruft, hat Kundenzufriedenheit Vorrang vor Ticketzeit.” Oder: „Bei Bestellungen über 500 Euro immer einen menschlichen Mitarbeiter hinzuziehen.”
Specification Engineering ist heute noch selten, wird aber mit zunehmender Autonomie von KI-Agenten zur Pflicht.
Warum Context Engineering Prompt Engineering ablöst
Die vier Stufen klingen in der Theorie logisch. Aber warum reicht Prompt Engineering in der Praxis nicht mehr aus?
Das Problem mit reinem Prompt Engineering:
Stellen Sie sich vor, Sie stellen einen neuen Mitarbeiter ein. Am ersten Tag erklären Sie ihm alles: Wer sind Ihre Kunden, wie läuft der Vertrieb, welche Tools nutzen Sie. Am zweiten Tag kommt er wieder. Und Sie erklären ihm alles nochmal. Von vorne. Jeden Tag.
Genau das machen die meisten mit KI. Jeder neue Chat ist wie ein Mitarbeiter mit Gedächtnisverlust.
Die Lösung: Einmal definieren, immer verfügbar.
Context Engineering beendet diesen Kreislauf. Sie bauen einmalig eine Wissensbasis auf, die Ihr KI-Agent bei jeder Session automatisch liest. Er weiß, wer Ihre Kunden sind, kennt Ihre Preise, versteht Ihren Ton und erinnert sich an vergangene Entscheidungen.
Was das in der Praxis bedeutet? Ich habe meine Website in 3 Tagen komplett neu gebaut. Nicht weil der KI-Agent besonders schlau ist. Sondern weil er meinen Kontext kannte: Meine Zielgruppe, mein Design, meine bestehenden Inhalte, meine SEO-Daten. Ohne diesen Kontext hätte er generische Ergebnisse geliefert.
Context Engineering in der Praxis: Die Wissensdatenbank
Was ist eine Wissensdatenbank?
Eine Wissensdatenbank kann vieles sein: Eine echte Datenbank, eine Vektordatenbank, ein Wiki oder auch einfach nur Textdateien in Ordnern. Entscheidend ist nicht das Format, sondern dass das Wissen strukturiert und für die KI zugänglich ist. In meinem Fall nutze ich einfache Textdateien. Kein Server, keine Software, keine Programmierkenntnisse nötig.
Aufbau: Ordner, Textdateien, Einstiegspunkt
Die Struktur ist einfach:
- Ein Hauptordner mit Unterordnern für jeden Bereich: Brand, Marketing, Vertrieb, Kunden, Design, Wissen.
- Eine Einstiegsdatei (bei mir heißt sie CLAUDE.md, bei anderen Tools heißt sie anders). Diese Datei ist bewusst kurz gehalten und enthält nur das Wichtigste: Wer bin ich, was macht meine Firma, wo findet der Agent welche Informationen.
- Bereichsspezifische Regeln in jedem Unterordner. Der Marketing-Ordner hat zum Beispiel eine eigene Regeldatei. Darin steht: Welche Social-Media-Kanäle ich nutze, wie mein Content-Workflow aussieht und dass 90% meiner Inhalte reinen Mehrwert liefern sollen, bevor ich mein Angebot erwähne.
Das Prinzip: Die Einstiegsdatei ist das Inhaltsverzeichnis. Sie sagt dem Agenten nur, wo er suchen muss. Die Details stehen in den Unterordnern.
Wie der KI-Agent navigiert
Wenn ich sage „Erstell mir einen Social-Media-Beitrag”, passiert Folgendes:
- Der Agent liest die Einstiegsdatei und weiß: Social Media gehört zum Bereich Marketing.
- Er navigiert in den Marketing-Ordner und liest dort die bereichsspezifischen Regeln.
- Er kennt jetzt meine Content-Strategie, meine Plattformen, meine Posting-Zeiten und meine verbotenen Phrasen.
- Erst dann erstellt er den Beitrag. Mit dem richtigen Ton, der richtigen Länge und auf der richtigen Plattform.
Alles automatisch. Ohne dass ich irgendetwas davon im Prompt erwähne.
Der versteckte Vorteil: Selbstpflegende Dokumentation
Die meisten Unternehmen kennen das Problem: Dokumentation wird einmal erstellt und dann nie wieder angeschaut. Nach sechs Monaten bildet sie nicht mehr die Realität ab. Es gibt zwei Versionen, niemand weiß welche aktuell ist. Der Pflegeaufwand ist so hoch, dass irgendwann keiner mehr dokumentiert.
Ich habe das in meiner Zeit bei Aldi selbst erlebt. Jede Änderung an einer Datenpipeline sollte dokumentiert werden. Warum gibt es dieses If-Statement? Welchen Sonderfall deckt es ab? In der Theorie wichtig. In der Praxis hat es niemand gemacht, weil der Aufwand zu groß war.
Mit einem KI-Agenten löst sich dieses Problem. Wenn ich ein neues Feature ausprobiere und es funktioniert, sage ich: „Dokumentier das.” Der Agent erstellt die Dokumentation selbst und legt sie an der richtigen Stelle ab.
Und es geht noch weiter: Jeder Fehler macht den Prozess besser.
Wenn mein KI-Agent einen Fehler macht, zum Beispiel das Angebot falsch strukturiert, sage ich ihm: „Das war falsch. Hinterleg als Regel, dass es ab jetzt so gemacht wird.” Beim nächsten Mal kennt er die Regel. Der Fehler passiert nicht wieder.
Mit jedem korrigierten Fehler wird die Wissensdatenbank robuster. Ohne dass ich eine Dokumentation öffnen, den Fehler suchen und manuell einpflegen muss.
Vendor-Lock-in vermeiden: Warum Ihr ChatGPT-Verlauf wertlos ist
Hier liegt ein Problem, das die meisten unterschätzen. Wenn Sie ChatGPT, Gemini oder Claude nutzen, speichern diese Tools Ihren Kontext intern. Custom GPTs, Projekt-Einstellungen, Chat-Verläufe. Alles liegt beim Anbieter.
Was passiert, wenn Sie wechseln wollen? Sie fangen bei Null an. Der gesamte Kontext, den Sie über Monate aufgebaut haben, ist weg. Sie müssen alles neu erklären. Und dann sind Sie enttäuscht, weil „das neue Tool nicht so gut ist wie das alte”.
In 90% der Fälle liegt das nicht am Tool. Es liegt am fehlenden Kontext.
Die Lösung: Bauen Sie Ihre Wissensdatenbank als Textdateien auf. Markdown-Dateien in Ordnern. Das funktioniert mit jedem KI-Tool: Claude Code, ChatGPT, Gemini, Cursor, Windsurf, Mistral. Egal welches LLM morgen das beste ist: Ihre Wissensdatenbank funktioniert weiterhin. Kopieren Sie den Ordner, und der neue Agent kann sofort loslegen.
Wir wissen nicht, welches Sprachmodell in zwei Jahren das beste sein wird. Was wir wissen: Textdateien wird es immer geben.
Context Engineering für Unternehmen
Knowledge Transfer: Wissen bleibt, wenn Mitarbeiter gehen
Das Schlimmste, was einem Unternehmen passieren kann: Ein Mitarbeiter, der seit zehn Jahren dabei ist, kündigt. Und sein Wissen geht mit ihm.
Mit einer KI-Wissensdatenbank passiert das nicht. Die Textdateien spiegeln das Wissen des Mitarbeiters wider: Seine Prozesse, seine Entscheidungslogik, seine Erfahrungswerte. Ein neuer Mitarbeiter kann den KI-Agenten fragen: „Wie erstelle ich ein Angebot?” Und bekommt eine Antwort, die auf dem Wissen seines Vorgängers basiert.
Cross-Team-Sharing: Eine Wissensbasis für alle
Stellen Sie sich vor, Ihr Marketing-Team definiert Brand-Guidelines: Farben, Schriftarten, Tonalität. Als Textdatei. Jeder KI-Agent im Unternehmen, egal ob im Vertrieb, im Support oder in der Produktentwicklung, kann diese Datei lesen. Automatisch. Kein Meeting, keine E-Mail, kein „Wo finde ich nochmal die aktuellen Farben?”.
Oder Ihr bester Vertriebler hat einen Prozess, der funktioniert: Bessere Recherche vor dem Erstgespräch, andere Fragen im Gespräch, konsequentere Follow-ups. Extrahieren Sie dieses Wissen in eine Textdatei und stellen Sie es allen Vertrieblern zur Verfügung. Jeder KI-Agent kennt dann den besten Prozess.
So starten Sie mit Context Engineering
Sie brauchen keine Software, keinen Entwickler und kein großes Setup. Drei Schritte reichen für den Anfang:
-
Einen Ordner anlegen. Erstellen Sie einen Ordner namens „Wissensdatenbank” mit Unterordnern für Ihre wichtigsten Bereiche: Kunden, Vertrieb, Marketing, Produkt.
-
Eine Einstiegsdatei schreiben. Beschreiben Sie in maximal 100 Zeilen: Wer sind Sie? Was macht Ihr Unternehmen? Wer ist Ihre Zielgruppe? Wo findet der Agent welche Informationen? Welche Regeln gelten immer?
-
Beim Arbeiten pflegen. Jedes Mal wenn die KI etwas falsch macht oder Sie ihr etwas Neues erklären, sagen Sie: „Hinterleg das als Regel.” So wächst Ihre Wissensdatenbank organisch, ohne zusätzlichen Aufwand.
Der Aufwand für den Start: Ein Tag. Die Zeitersparnis danach: Bei mir sind es über 12 Stunden pro Woche allein im Content-Bereich. Social-Media-Content, der früher 14 Stunden gedauert hat, erledige ich jetzt in 2 Stunden. Weil mein KI-Assistent den Kontext bereits kennt.
Fazit
Prompt Engineering war der richtige Einstieg in die KI-Nutzung. Aber es reicht nicht mehr. Wer jedes Mal bei Null anfängt, verschwendet Zeit und bekommt generische Ergebnisse.
Context Engineering ist der nächste Schritt: Einmal Ihr Firmenwissen strukturieren, dauerhaft verfügbar machen und mit jedem Fehler verbessern. Die Wissensdatenbank dafür ist keine technische Herausforderung. Es sind Textdateien in Ordnern. Kein Server, keine Datenbank, keine Programmierkenntnisse.
Der beste Zeitpunkt damit anzufangen war gestern. Der zweitbeste ist heute. Je früher Sie starten, desto mehr Wissen sammelt Ihr KI-Agent und desto besser werden die Ergebnisse.
Häufig gestellte Fragen (FAQ)
Was ist der Unterschied zwischen Prompt Engineering und Context Engineering?
Prompt Engineering optimiert die einzelne Anweisung an die KI. Context Engineering optimiert das dauerhafte Wissen, auf das die KI bei jeder Interaktion zugreift. Der Prompt sagt „Was soll die KI tun?”, der Kontext sagt „Was weiß die KI über mich und mein Unternehmen?”.
Brauche ich technisches Wissen für Context Engineering?
Nein. Eine Wissensdatenbank besteht aus Textdateien in Ordnern. Wenn Sie einen Ordner erstellen und eine Textdatei schreiben können, können Sie Context Engineering betreiben. Es gibt keine Datenbank, keinen Server und keinen Code.
Welches Tool eignet sich am besten für eine KI-Wissensdatenbank?
Das hängt von Ihrem Anwendungsfall ab. Für agentenbasiertes Arbeiten eignen sich Tools wie Claude Code oder Cursor, die Dateien direkt lesen können. Wichtig ist: Bauen Sie die Wissensdatenbank als Textdateien auf, nicht innerhalb eines einzelnen Tools. So vermeiden Sie Vendor-Lock-in.
Funktioniert Context Engineering auch mit ChatGPT?
Ja, aber eingeschränkt. ChatGPT bietet Custom Instructions und Projekte, in denen Sie Kontext hinterlegen können. Der Nachteil: Dieser Kontext ist an ChatGPT gebunden. Wenn Sie wechseln, müssen Sie ihn neu aufbauen. Eine dateibasierte Wissensdatenbank ist portabler.
Wie lange dauert es, eine Wissensdatenbank aufzubauen?
Der Grundaufbau dauert etwa einen Tag: Ordnerstruktur anlegen, Einstiegsdatei schreiben, die wichtigsten Regeln definieren. Danach wächst die Wissensdatenbank organisch bei der täglichen Arbeit. Jeder korrigierte Fehler und jede neue Regel macht sie besser.
Fabian Stegmaier
KI-Automatisierung & n8n-Experte aus Salzburg. Ich helfe KMU im DACH-Raum bei der Implementierung intelligenter Workflows.
Mehr erfahren →